Load balancing
One of the ultimate goals for DRPC is to connect user request and the best data provider for this specific request.
What’s the best provider?
- The one that at least have possibility of fulfilling request (obviously!). For all networks that DRPC supports there are a lot of different methods with different parameters, specifics, quirks, etc. DRPC’s providers vary greatly, so this task is actually quite hard
- The one that has the lowest possible latency and error probability. We want request to be served as fast as possible and without errors.
- That said, we don’t want our service to work on “winner takes it all” principle. Ultimately, most of the providers should receive a portion of requests depending on their performance
- However, we don’t want to balance requests to providers who will fulfil given request with very low probability. Otherwise, developer experience with DRPC would be awful.
Balancing overview
Load balancing is tricky process and consists of several stages, let’s review them. Let’s say we have a request — typical JSON RPC request, what’s next?
Strategy selection
The first thing we need to do with request is to select load balancing strategy for it. Strategy defines the overall algorithm for provider selection.
Strategy can be expressed as an interface:
type Strategy interface {
Next(providers int) ([]subjective.View[reducerstates.Address, reducerstates.ProviderId], error)
GetProviders(factual bool) []reducerstates.ProviderId
Receive(reducerstates.ProviderId) bool
}We will elaborate it later, but the main method is Next which returns us some amount of providers (at least the amount we requested, but may return more).
Currently, DRPC supports following strategies:
- One-off strategy, this strategy is used when there is ultimately one provider that should handle current request and we do not plan on any retries. For example, for requests that use sticky session (like
eth_getFilterChanges) - Strategy with retries, this is used in all cases except when one-off strategy is used, so we will talk about it.
Detailed description is here.
So, say for our request we selected strategy with retries. After that our request becomes routed request.
Request execution flow
All routed requests then passed to execution flow. We use simple example with one request, in reality for batch request there can be a lot of request going through execution flow in parallel.
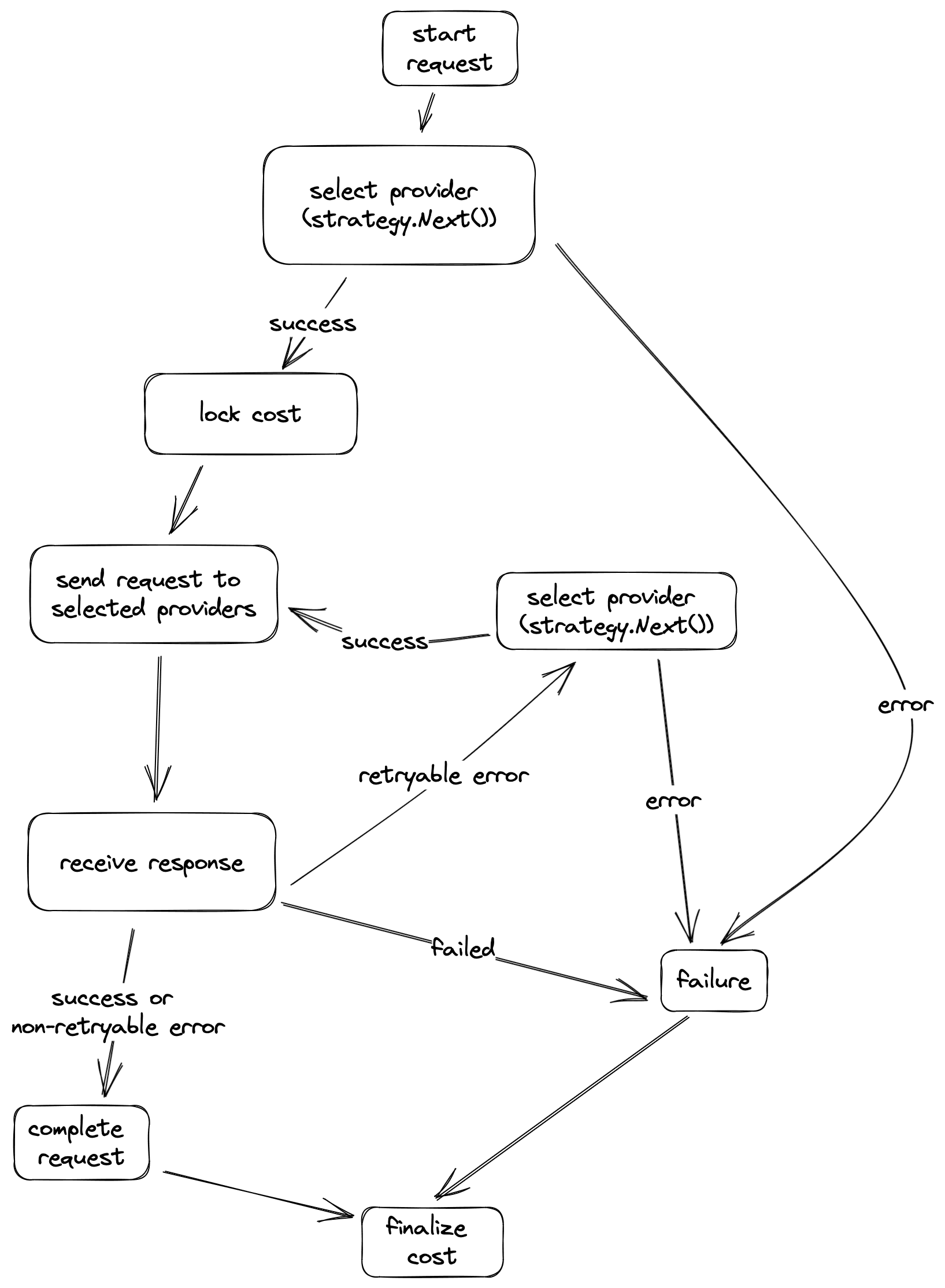
In the diagram above we can see that each request passed those stages.
Start
We start request and notify all systems that are interested that certain request is started.
Select provider
Now we use our request strategy to determine the providers we want to send this request to. Simple case its one provider per request, however there is a verification feature that requires multiple responses from distinct providers for each request.
Provider selection is lazy, so there is a possibility that given strategy can’t select appropriate provider, in this case we consider request failed. We do not charge money for failed request.
If strategy returned us some providers, we move next.
Lock cost
Due to the fact that we do not know how much retries and to which providers we decide to do. We deduct money in two steps. After first provider selection we “lock” the cost for best case scenario.
We need to check that user is capable of paying this price at least.
Send request to provider
This is basically an event for those who interested in it.
Receive response
We receive some response from provider there are few options:
- Request failed. It means something unexpected happened during request processing somewhere (DRPC-side or provider-side). We consider this request a failure.
- An error occurred, but we think it’s wise to retry. There are different errors that can produce a good result if sent to another provider. May be it’s due to the provider faulty behaviour or other “retryable reasons”.
- We then try to select another provider and if succeed we move to send request to provider stage
- Otherwise, we consider request failed
- We receive success or error that we think is not retryable (for example malformed request). This way we consider request completed.
This is also an event.
Complete request
The main thing that occurs here is that we use strategy.Receive method to notify strategy that we successfully received response from provider. We need it to calculate final cost
This is an event.
Finalize cost
This is the final stage of execution flow. We calculate the final cost for request and correct locked cost. This way we deduct the exact amount for useful work our providers performed. More about how we deduct payments here.
Note on geographical load balancing
The last thing we want to talk about here is geo load balancing. We describe how it affects rating here. However, there are few important facts about infrastructure we have for that purpose.
Currently, we have 2 deployments in US Central and Europe West. We use Cloudflare geo load balancing, so your request automatically routed to our closest deployment.
Usually we will always prioritise providers from the same region, however it is possible that sometimes (for example if you allow only sending requests to specific providers) we will send your request cross-region, which can add few hundreds of milliseconds of latency.
Internally, we treat different regions of the same provider as separate providers, they will have their separate rating, etc.
Overall, we strive for lowest latency and being located in different regions helps us a lot. We also try to localise data that we need to process request. So, all reads always go to the local copy of DB. We use Scylla DB (opens in a new tab) which allows us to replicate data across datacenters without any manual configuration.